 PreDaTor - Machine Learning Modelle
PreDaTor - Machine Learning ModelleKünstliche Intelligenz und maschinelles Lernen sind der Teil der Informatik, der miteinander korreliert. Diese beiden Technologien sind die angesagtesten Technologien, die zur Schaffung intelligenter Systeme verwendet werden. Obwohl dies zwei verwandte Technologien sind und manchmal als Synonyme verwendet werden, sind beide in verschiedenen Fällen zwei unterschiedliche Begriffe. Auf einer breiten Ebene können wir sowohl KI als auch ML wie folgt unterscheiden: KI ist ein umfassenderes Konzept zur Schaffung intelligenter Maschinen, die menschliches Denkvermögen und Verhalten simulieren können, während maschinelles Lernen eine Anwendung oder Teilmenge der KI ist, die es Maschinen ermöglicht, aus Daten zu lernen, ohne explizit programmiert zu werden.
Maschinelles Lernen Ein Programm oder System (z.B. Predator), das ein Vorhersagemodell aus Eingabedaten erstellt, dem sogenannten Training. Das System verwendet das erlernte Modell, um nützliche Vorhersagen aus neuen (noch nie zuvor gesehenen) Daten zu treffen (z.B. Predator Sandbox), die aus derselben Verteilung stammen wie die, die zum Trainieren des Modells verwendet wurde. Maschinelles Lernen bezieht sich auch auf das Studiengebiet, das sich mit diesen Programmen oder Systemen befasst.
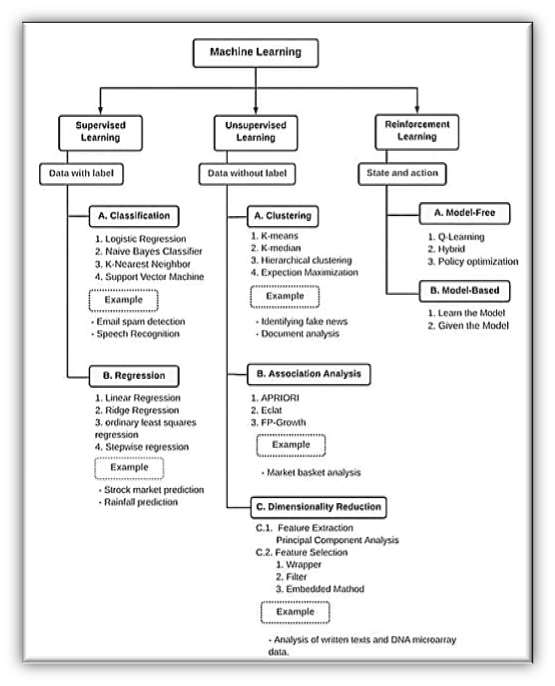
Regression vs. Klassifikation beim maschinellen Lernen: Regressions- und Klassifizierungsalgorithmen sind überwachte Lernalgorithmen. Beide Algorithmen werden für die Vorhersage beim maschinellen Lernen verwendet und arbeiten mit den gekennzeichneten Datensätzen. Der Unterschied zwischen beiden besteht jedoch darin, wie sie für verschiedene Probleme des maschinellen Lernens verwendet werden. Der Hauptunterschied zwischen Regressions- und Klassifizierungsalgorithmen besteht darin, dass Regressionsalgorithmen verwendet werden, um die kontinuierlichen Werte wie Preis, Gehalt, Alter usw. vorherzusagen, und Klassifizierungsalgorithmen verwendet werden, um die diskreten Werte wie männlich oder weiblich, wahr oder falsch vorherzusagen/zu klassifizieren. Spam oder kein Spam usw.
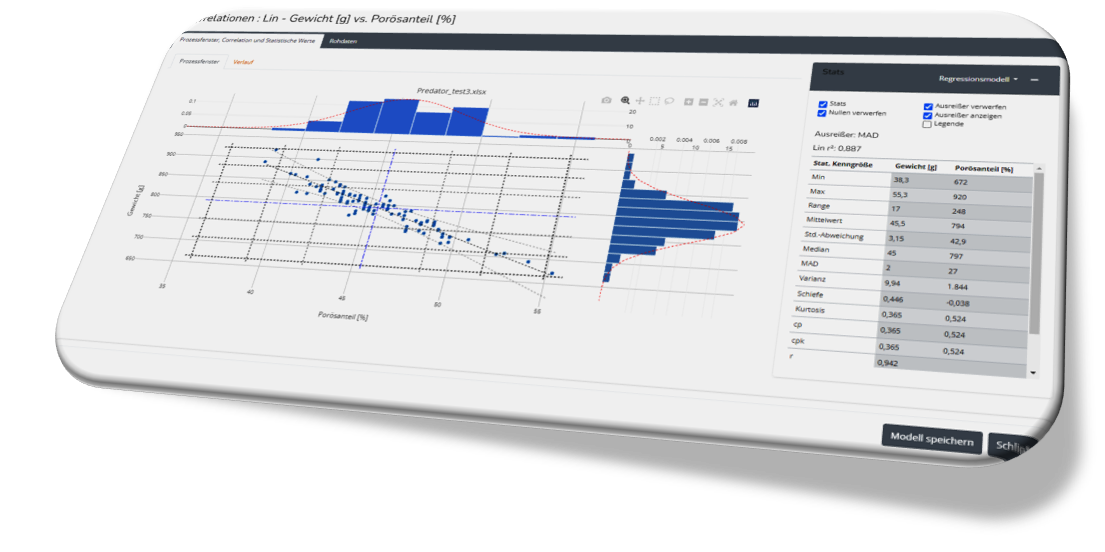
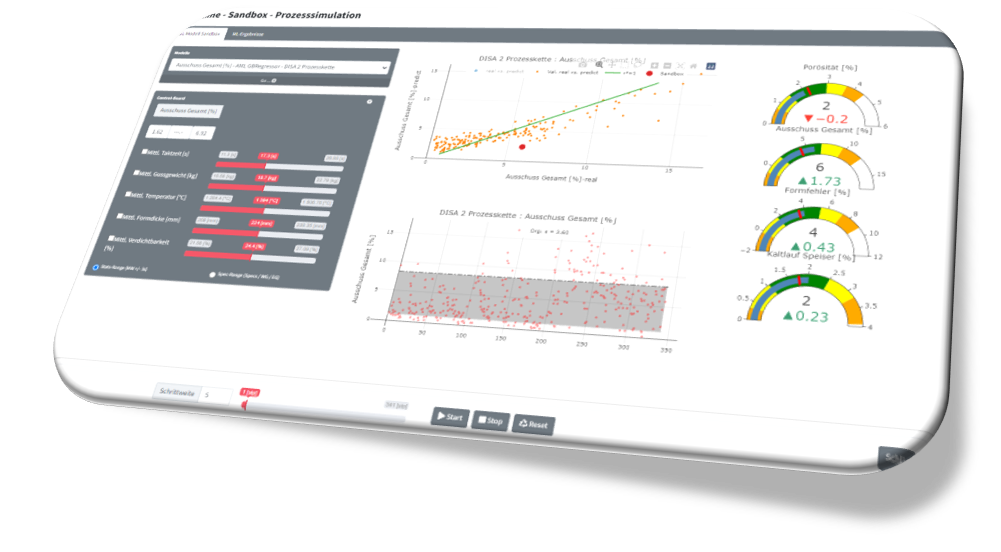
Regression : Regression ist ein Prozess zum Auffinden der Korrelationen zwischen abhängigen und unabhängigen Variablen. Es hilft bei der Vorhersage der kontinuierlichen Variablen wie der Vorhersage von Markttrends, der Vorhersage von Hauspreisen usw. Die Aufgabe des Regressionsalgorithmus besteht darin, die Abbildungsfunktion zu finden, um die Eingabevariable (x) auf die kontinuierliche Ausgabevariable (y) abzubilden. Beispiel: Angenommen, wir möchten Wettervorhersagen erstellen, also verwenden wir dafür den Regressionsalgorithmus. Bei der Wettervorhersage wird das Modell mit den vergangenen Daten trainiert, und sobald das Training abgeschlossen ist, kann es das Wetter für zukünftige Tage leicht vorhersagen. Arten von Regressionsalgorithmen:
- Simple Linear Regression
- Multiple Linear Regression
- Polynomial Regression
- Support Vector Regression
- Decision Tree Regression
- Random Forest Regression
- Gradient Descent Regression
Classification : Einstufung: Die Klassifizierung ist ein Prozess, bei dem eine Funktion gefunden wird, die dabei hilft, den Datensatz basierend auf verschiedenen Parametern in Klassen zu unterteilen. Bei der Klassifizierung wird ein Computerprogramm mit dem Trainingsdatensatz trainiert und kategorisiert die Daten basierend auf diesem Training in verschiedene Klassen. Die Aufgabe des Klassifizierungsalgorithmus besteht darin, die Abbildungsfunktion zu finden, um die Eingabe (x) auf die diskrete Ausgabe (y) abzubilden. Beispiel: Das beste Beispiel zum Verständnis des Klassifizierungsproblems ist die E-Mail-Spam-Erkennung. Das Modell wird anhand von Millionen von E-Mails auf verschiedene Parameter trainiert und erkennt bei jeder neuen E-Mail, ob es sich um Spam handelt oder nicht. Wenn es sich bei der E-Mail um Spam handelt, wird sie in den Spam-Ordner verschoben. Arten von ML-Klassifizierungsalgorithmen:
- Logistic Regression
- K-Nearest Neighbour
- Support-Vektor-Maschine
- Kernel-SVM
- Naive Bayes
- Descission Tree Klassifizierung
- Random Forest-Klassifizierung
Vorraussetzung für die Regression ist, dass die Ausgabevariable von kontinuierlicher Natur oder von realem Wert ist. In der Klassifizierung muss die Ausgabevariable ein diskreter Wert sein. Die Aufgabe des Regressionsalgorithmus besteht darin, den Eingabewert (x) der kontinuierlichen Ausgabevariablen (y) zuzuordnen. Die Aufgabe des Klassifikationsalgorithmus besteht darin, den Eingabewert(x) der diskreten Ausgabevariable(y) zuzuordnen. Regressionsalgorithmen werden mit kontinuierlichen Daten verwendet. Klassifizierungsalgorithmen werden mit diskreten Daten verwendet. In der Regression versuchen wir, die beste Anpassungslinie ober Regressionslinie zu finden, die die Ausgabe genauer vorhersagen kann. In der Klassifikation versuchen wir, die Entscheidungsgrenze zu finden, die den Datensatz in verschiedene Klassen unterteilen kann. Regressionsalgorithmen können verwendet werden, um die Regressionsprobleme wie Wettervorhersage, Hauspreisvorhersage usw. zu lösen.Klassifizierungsalgorithmen hingegen helfen bei der Identifizierung von Spam-E-Mails, Spracherkennung und der Identifizierung von Krebszellen. Der Regressionsalgorithmus kann weiter in lineare und nichtlineare Regression unterteilt werden. Klassifikationsalgorithmen sind die Binary Classifier und die Multi-Class Classifier.