graph TD
A[Mermaid setup erfolgreich geladen]
PreDaTor - Hilfe
-
Quick Start - Login und Daten laden
Starten wir mit der Bedienoberfläche der PreDaTor-App. Es gibt hier die klassische Aufteilung Top-Menu mit den Navigationselementen,
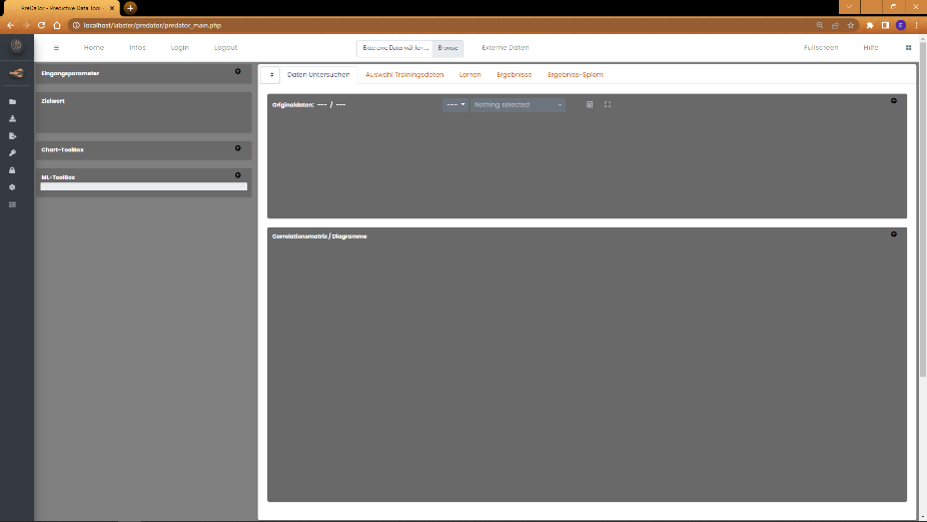 Left-Side-Menu und Right-Side-Menu mit den Einstellungen (mit Klick auf die 4-fach Kachel oben rechts)
Left-Side-Menu und Right-Side-Menu mit den Einstellungen (mit Klick auf die 4-fach Kachel oben rechts)
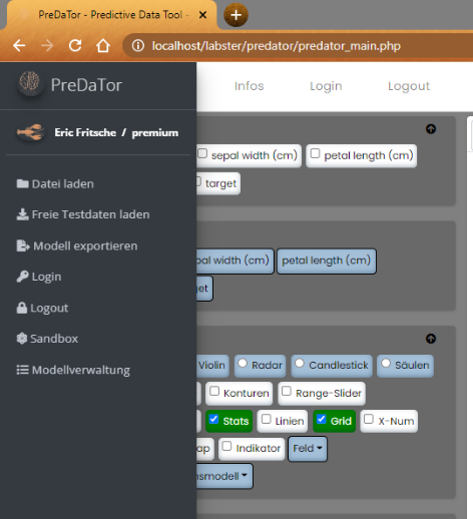
 Vorab : der Login ist nicht zwingend zum Testen des Systems. Mit vorhandenem Account lassen sich jedoch interessante
Features freischalten. Zum Beispiel die zusätzliche Funktion, aus verschiendenen Tabs einer Excel Datei auszuwählen,
zusätzliche ML-Methode und die Möglichkeit die berechneten Modelle zu speichern und zum späteren Zeitpunkt wieder zu verwenden.
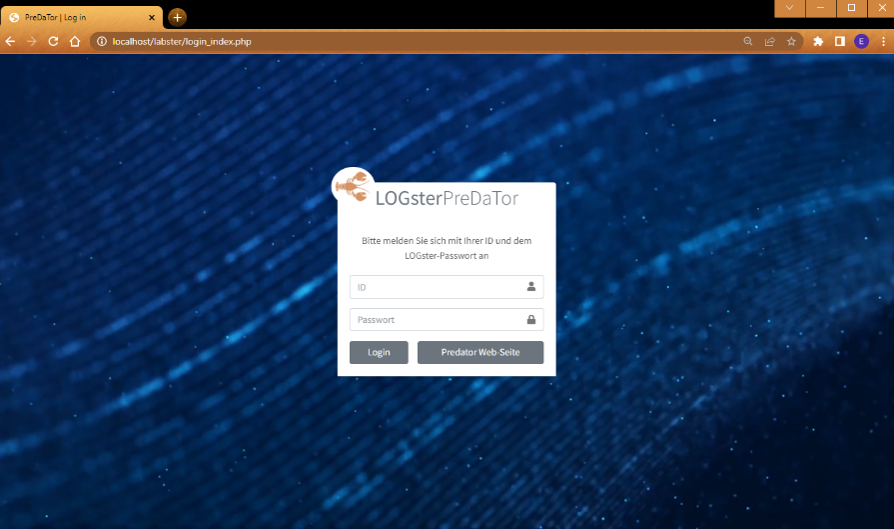
Hier geht's zur Anmeldung
Wenn Sie bereits einen Account haben, klicken Sie "Login" an, worauf das Fenster zur Anmeldung aufgeht.
Nach Angabe das User-Namens und des Passwortes, werden die gebuchten zusätzlichen Features angezeigt.
Vorab : der Login ist nicht zwingend zum Testen des Systems. Mit vorhandenem Account lassen sich jedoch interessante
Features freischalten. Zum Beispiel die zusätzliche Funktion, aus verschiendenen Tabs einer Excel Datei auszuwählen,
zusätzliche ML-Methode und die Möglichkeit die berechneten Modelle zu speichern und zum späteren Zeitpunkt wieder zu verwenden.
Hier geht's zur Anmeldung
Wenn Sie bereits einen Account haben, klicken Sie "Login" an, worauf das Fenster zur Anmeldung aufgeht.
Nach Angabe das User-Namens und des Passwortes, werden die gebuchten zusätzlichen Features angezeigt.
 Zentraler Beginn aller Aktionen, ist die die Auswahl des zu analysierenden Datensatzes. Stehen keine eigene Daten im
CSV, TXT, Excel oder JSON Fomat zur Verfügung, kann für die ersten Tests aus der Liste freier Datensätze die entsprechende
Datei heruntergeladen werden. Klicken Sie hierzu auf "Externe Daten".
Zentraler Beginn aller Aktionen, ist die die Auswahl des zu analysierenden Datensatzes. Stehen keine eigene Daten im
CSV, TXT, Excel oder JSON Fomat zur Verfügung, kann für die ersten Tests aus der Liste freier Datensätze die entsprechende
Datei heruntergeladen werden. Klicken Sie hierzu auf "Externe Daten".
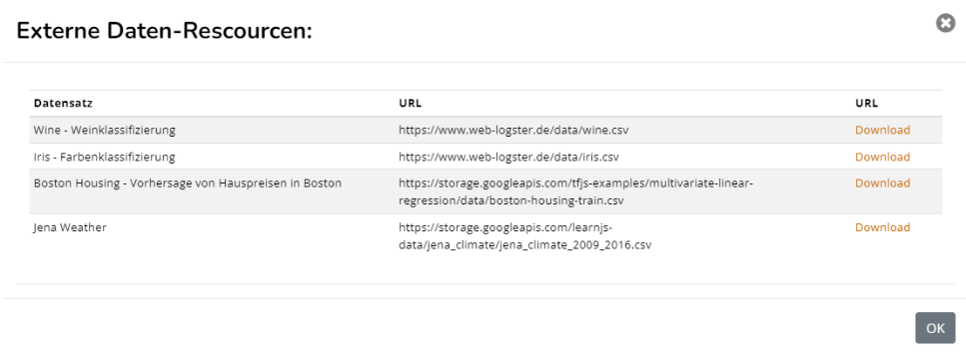 Laden Sie mit einem Klick auf das "Download"-Feld die Datei herunter. Typischer Weise befindet sich diese Datei nun in
Ihrem "Download"-Ordner. Schließen Sie das Fenster ("OK" oder "x"). Über den "Browse"-Button, der sich auf der oberen
Menue-Leiste in der Mitte befindet, wählen Sie die heruntergeladene Datei aus dem Download Ordner aus.
So können Sie auch eigene Dateien als Datenbasis für Ihre Auswertungen laden.
Hat alles funktioniert, sollten Sie folgendes sehen:
Laden Sie mit einem Klick auf das "Download"-Feld die Datei herunter. Typischer Weise befindet sich diese Datei nun in
Ihrem "Download"-Ordner. Schließen Sie das Fenster ("OK" oder "x"). Über den "Browse"-Button, der sich auf der oberen
Menue-Leiste in der Mitte befindet, wählen Sie die heruntergeladene Datei aus dem Download Ordner aus.
So können Sie auch eigene Dateien als Datenbasis für Ihre Auswertungen laden.
Hat alles funktioniert, sollten Sie folgendes sehen:
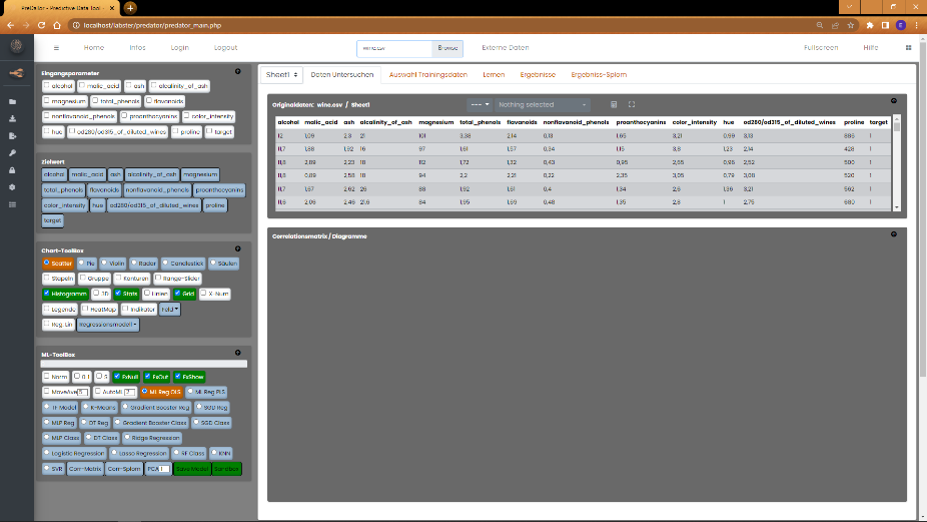 Auf der rechten Seite sehen Sie nun die zur Verfügung stehenden Namen der Tabellenfelder sowohl als Eingangsparameter
(Mehrfachauswahl), als auch im Feld der Zielgrößen der ML-Modelle. Darunter befinden sich die Tool-Boxen für die
Datenvisualisierung und die Erstellung der ML-Modelle. Rechts oben befinden sich einige Tabs. Nach dem Laden der Daten wird
automatisch der Tab für die Darstellung der Tabelle mit den Basisdaten und der Datenvisualisierung geöffent.
In der PRO-Version finden Sie an erster Stelle den Tab "Sheets". Falls Sie eine Microsoft Excel Tabelle geladen haben,
welche mehrere Seiten enthält, können Sie hier die gewünschte Seite auswahlen. In der Basic Variante wird im Fall einer
Multi-Sheet-Datei die Erste ausgewählt.
Weiter geht's mit der Datenanalyse.
Auf der rechten Seite sehen Sie nun die zur Verfügung stehenden Namen der Tabellenfelder sowohl als Eingangsparameter
(Mehrfachauswahl), als auch im Feld der Zielgrößen der ML-Modelle. Darunter befinden sich die Tool-Boxen für die
Datenvisualisierung und die Erstellung der ML-Modelle. Rechts oben befinden sich einige Tabs. Nach dem Laden der Daten wird
automatisch der Tab für die Darstellung der Tabelle mit den Basisdaten und der Datenvisualisierung geöffent.
In der PRO-Version finden Sie an erster Stelle den Tab "Sheets". Falls Sie eine Microsoft Excel Tabelle geladen haben,
welche mehrere Seiten enthält, können Sie hier die gewünschte Seite auswahlen. In der Basic Variante wird im Fall einer
Multi-Sheet-Datei die Erste ausgewählt.
Weiter geht's mit der Datenanalyse.
-
Quick Start - Datenanalyse
Für die Steuerung der Datenvisualisierung dient die "Chart Toolbox". Diese befindet sich im linken, mittleren Segment des Hauptbildschirms.
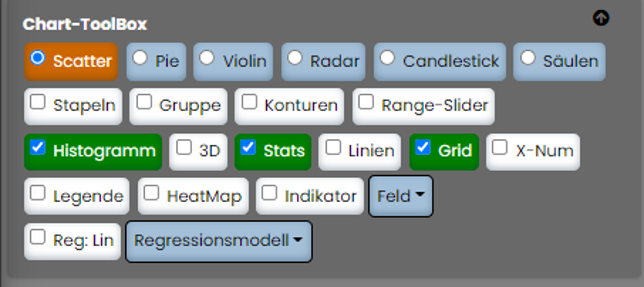 Die einfachste Art die geladenen Daten darzustellen, ist ein Doppelklick auf die entsprechende Spalte in der Tabelle.
In der Chart-Sektion wird das Diagramm dargestellt. Voreingestellt ist der Scatterplot. Bei nicht vorhandener Datumsspalte
wird automatisch der "X-Num"-Modus aktiviert. Hier wird die fortlaufende Nummer des Datensatzes auf der x-Achse und der
entsprechende Wert auf der y-Achse als Punktwolke angezeigt. Ist ein Datumsfeld vorhanden wird das entsprechende Datum auf
der x-Achse aufgetragen.
Ebenfalls als Voreinstellung, wird das Verteilungsdiagramm (rechts), die 3s-Streuung und Ausreißer als rote Markierung
auf MAD Basis angezeigt.
Rechts neben dem Chart sind die statistischen Kennwerte der Datenmenge tabellarisch aufgelistet.
(Mittelwert, Std-Abweichung, Median, Varianz, etc).
Nach dem Doppelklick auf die Tabellenspalte, sollte sich dann folgendes Bild ergeben:
Die einfachste Art die geladenen Daten darzustellen, ist ein Doppelklick auf die entsprechende Spalte in der Tabelle.
In der Chart-Sektion wird das Diagramm dargestellt. Voreingestellt ist der Scatterplot. Bei nicht vorhandener Datumsspalte
wird automatisch der "X-Num"-Modus aktiviert. Hier wird die fortlaufende Nummer des Datensatzes auf der x-Achse und der
entsprechende Wert auf der y-Achse als Punktwolke angezeigt. Ist ein Datumsfeld vorhanden wird das entsprechende Datum auf
der x-Achse aufgetragen.
Ebenfalls als Voreinstellung, wird das Verteilungsdiagramm (rechts), die 3s-Streuung und Ausreißer als rote Markierung
auf MAD Basis angezeigt.
Rechts neben dem Chart sind die statistischen Kennwerte der Datenmenge tabellarisch aufgelistet.
(Mittelwert, Std-Abweichung, Median, Varianz, etc).
Nach dem Doppelklick auf die Tabellenspalte, sollte sich dann folgendes Bild ergeben:
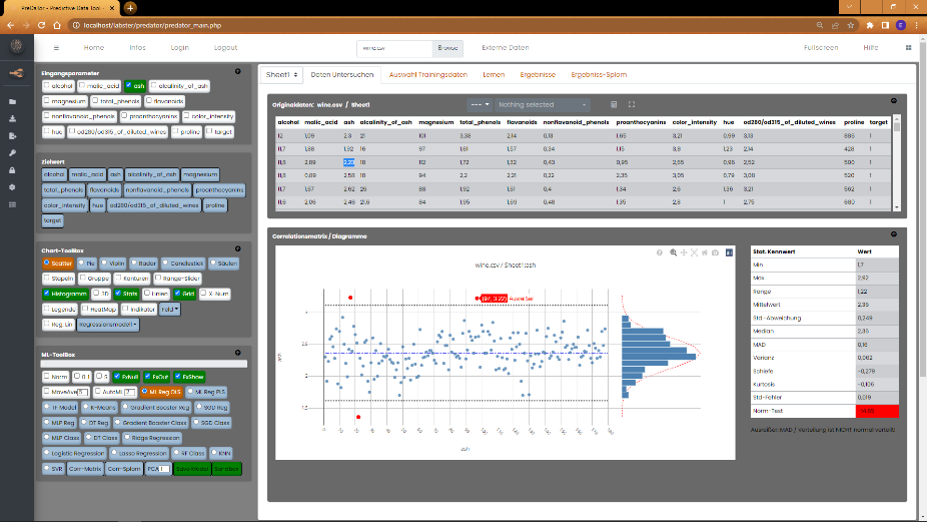 Sie können die Spalten einzeln durchklicken und die Verteilung der Datensätze analysieren.
Soll das Verhältnis zweier Parameter dargestellt werden, wählen Sie aus den Eingangsparametern zwei Felder aus den Eingangsparametern
aus und klicken in der "Chart Toolbox" auf "Scatter".
Sie können die Spalten einzeln durchklicken und die Verteilung der Datensätze analysieren.
Soll das Verhältnis zweier Parameter dargestellt werden, wählen Sie aus den Eingangsparametern zwei Felder aus den Eingangsparametern
aus und klicken in der "Chart Toolbox" auf "Scatter".
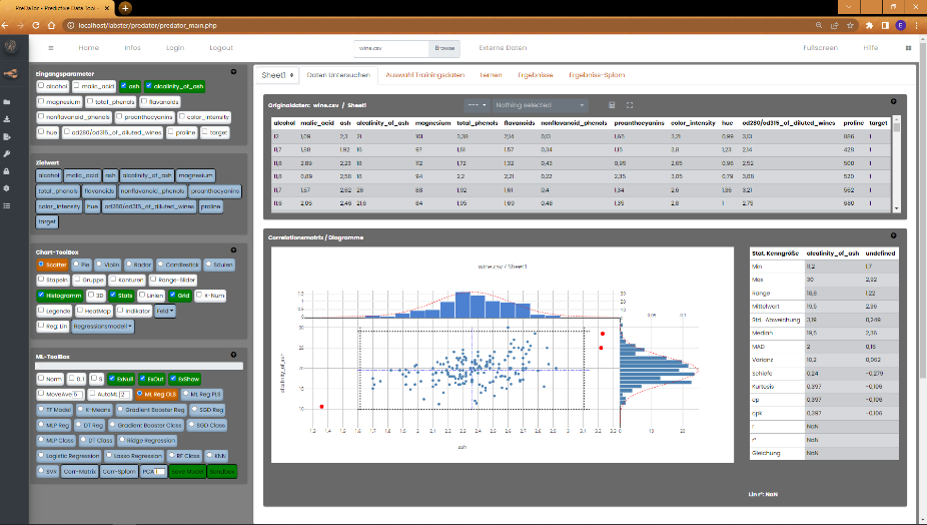 Einen guten Überblick über das Verhältnis der Parameter untereinander, bieten die Features "Korrelationsmatrix" und "Splom".
Beide Funktionen sind in der "ML-Toolbox" zu finden und stehen in jeder Version zur Verfügung.
Einen guten Überblick über das Verhältnis der Parameter untereinander, bieten die Features "Korrelationsmatrix" und "Splom".
Beide Funktionen sind in der "ML-Toolbox" zu finden und stehen in jeder Version zur Verfügung.
 Wählen Sie aus den Eingangsparametern die Felder, die Sie untereinander vergleichen wollen. Mindestens zwei Felder müssen
hierfür ausgewählt sein. Nach einem Klick auf "Corr-Matrix" in der ML-Toolbox, erzeugt PreDaTor aus den Daten folgende Matrix-Darstellung.
Wählen Sie aus den Eingangsparametern die Felder, die Sie untereinander vergleichen wollen. Mindestens zwei Felder müssen
hierfür ausgewählt sein. Nach einem Klick auf "Corr-Matrix" in der ML-Toolbox, erzeugt PreDaTor aus den Daten folgende Matrix-Darstellung.
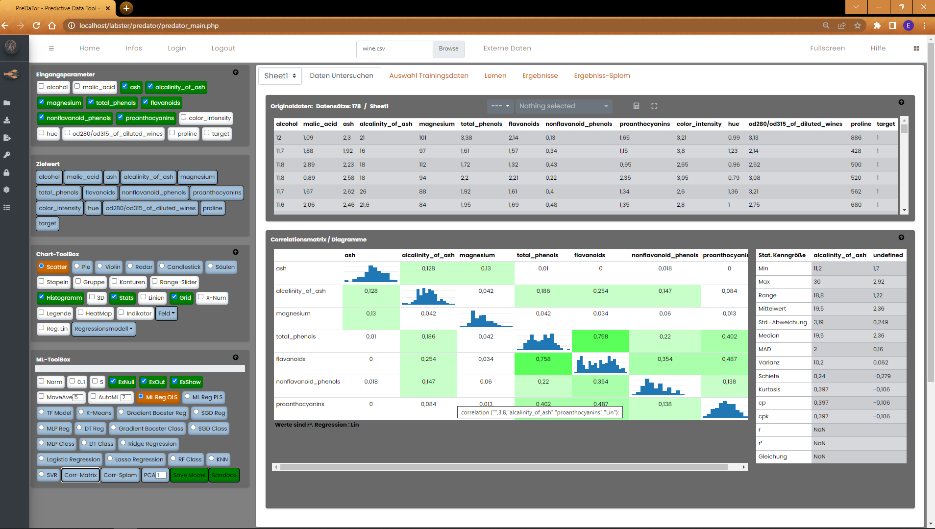 Die Parameter werden auf der jeweils x- und y-Achse tabellarisch dargestellt. In dem jeweiligen Kreuzungsfeld,
d.h. Parameter n auf der x-Achse kreuzt Parameter n auf der y-Achse, wird die Verteilung der Daten als Histogramm dargestellt.
In den n/m-Kreuzungsfeldern wird das aus den Datensätzen resultirende Bestimmtheitsmaß r² dargestellt. Für das
Bestimmtheitsmaß gilt : 0 = keine Korrelation der Daten ; 1 = 100%ige Korrelation der Daten. Das Matrixfeld färbt
sich bei höheren r² in entsprechend abgestuften Grüntönen (Dunkelgrün = 1).
Ein Doppelklick auf eins dieser Felder stellt die statistische Abhängigkeit im Stats-Modul graphisch dar.
Die Parameter werden auf der jeweils x- und y-Achse tabellarisch dargestellt. In dem jeweiligen Kreuzungsfeld,
d.h. Parameter n auf der x-Achse kreuzt Parameter n auf der y-Achse, wird die Verteilung der Daten als Histogramm dargestellt.
In den n/m-Kreuzungsfeldern wird das aus den Datensätzen resultirende Bestimmtheitsmaß r² dargestellt. Für das
Bestimmtheitsmaß gilt : 0 = keine Korrelation der Daten ; 1 = 100%ige Korrelation der Daten. Das Matrixfeld färbt
sich bei höheren r² in entsprechend abgestuften Grüntönen (Dunkelgrün = 1).
Ein Doppelklick auf eins dieser Felder stellt die statistische Abhängigkeit im Stats-Modul graphisch dar.
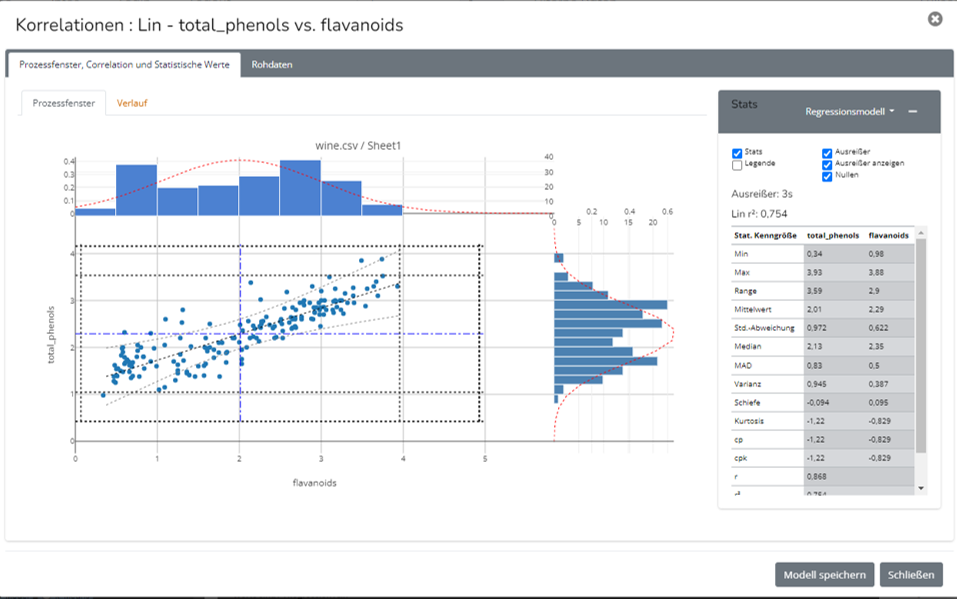 Neben der Punktwolke, den Verteilungen oben und rechts und den statistischen Kennwerten x/, +/-1,2,3 s, wird ebenfalls die
resultierende Korrelationsgrade inkl. der Konfidenzintervalle dargestellt. In der Toolbox oben rechts, findet sich ein Auswahlfeld,
aus welchem man die gewünschte Regressionsfunktion auswählt. Es stehen neben der linearen auch die logarhythmische, exponentielle,
potenz- sowie die polinomialen Funktionen 2-5 Grades zur Verfügung.
Sowohl in der ML-Toolbox als auch im Stats-Modul stehen Funktionen zur schnellen Datenfilterung zur Verfügung. Die jeweiligen
Schaltfelder "Ex-Null", entfernen Datensätze in denen Nullen vorhanden sind. "Ex-Out"-Schaltflächen eliminieren
Ausreißer aus der Grundgesamtheit. (Ausreißersuche gemäß Median/MAD oder x/s in "Einstellungen" auswählbar.)
Neben der Punktwolke, den Verteilungen oben und rechts und den statistischen Kennwerten x/, +/-1,2,3 s, wird ebenfalls die
resultierende Korrelationsgrade inkl. der Konfidenzintervalle dargestellt. In der Toolbox oben rechts, findet sich ein Auswahlfeld,
aus welchem man die gewünschte Regressionsfunktion auswählt. Es stehen neben der linearen auch die logarhythmische, exponentielle,
potenz- sowie die polinomialen Funktionen 2-5 Grades zur Verfügung.
Sowohl in der ML-Toolbox als auch im Stats-Modul stehen Funktionen zur schnellen Datenfilterung zur Verfügung. Die jeweiligen
Schaltfelder "Ex-Null", entfernen Datensätze in denen Nullen vorhanden sind. "Ex-Out"-Schaltflächen eliminieren
Ausreißer aus der Grundgesamtheit. (Ausreißersuche gemäß Median/MAD oder x/s in "Einstellungen" auswählbar.)
 Bleibt noch die Darstellung des Splom; der Scatter Plot Matrix! Die Funktion "Corr-Splom" ist in der ML-Toolbox
zu finden und stellt, ähnlich wie die Korrelationsmatrix, das Verhältnis zweier Parameter dar. Allerdings wird
das Verhältnis nicht numerisch, sondern graphisch dargestellt. Die Vorgehensweise funktioniert genau wie bei "Corr-Matrix".
Auwahl der darzustellenden Parameter, und ein Klick auf die Schaltfläche.
Bleibt noch die Darstellung des Splom; der Scatter Plot Matrix! Die Funktion "Corr-Splom" ist in der ML-Toolbox
zu finden und stellt, ähnlich wie die Korrelationsmatrix, das Verhältnis zweier Parameter dar. Allerdings wird
das Verhältnis nicht numerisch, sondern graphisch dargestellt. Die Vorgehensweise funktioniert genau wie bei "Corr-Matrix".
Auwahl der darzustellenden Parameter, und ein Klick auf die Schaltfläche.
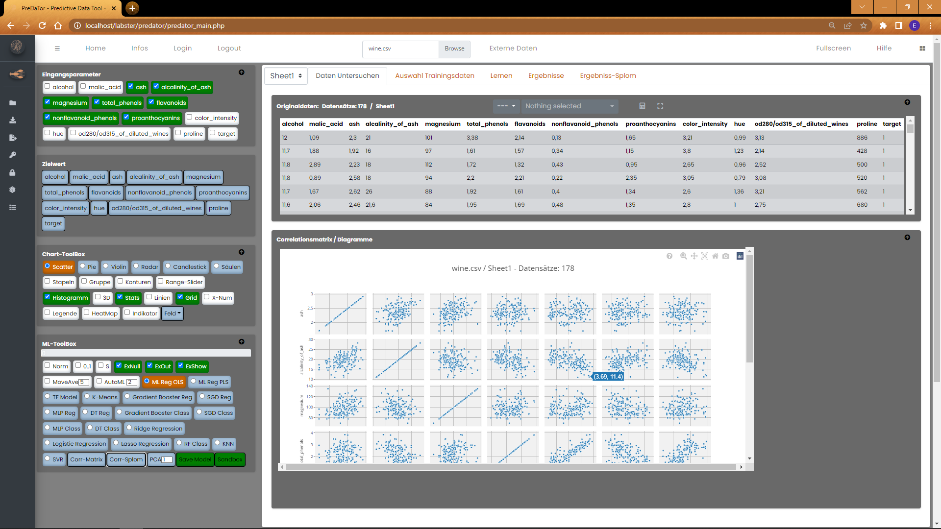 Wie auch bei der Korrelationsmatrix, gelangen Sie mittels Doppelklick auf das entsprechende Feld in das Stats-Modul zur weiteren Analyse.
Jetzt zu der Erstellung von Modellen..
Wie auch bei der Korrelationsmatrix, gelangen Sie mittels Doppelklick auf das entsprechende Feld in das Stats-Modul zur weiteren Analyse.
Jetzt zu der Erstellung von Modellen..
-
Quick Start - Erstellen von Modellen
Die einfachste Version eines Datenmodells ist die einfache linare Regression. Diese haben wir schon im Stats-Modul kennengelernt. Soll über mehrere Eingangsparameter ein Ziel korreliert werden, ist in diesem Kontext die multiple lineare Regressionsanalyse eine erste Wahl. Um ein erstes Modell zu erstellen, laden Sie hierzu den entsprechenden Datensatz über den Browse-Button. Es stehen zwei Ansätze für die multiple linerare Regressionsnanalyse zu Verfügung. OLS, Ordinary Least Square und PLS , Partial Least Square. Der mathematisch Hintergrund ist hier zu finden (OLS | PLS). Klicken Sie die Eingangsparameter an, mit denen Sie das Vorhersagemodell erstellen wollen. Klicken Sie in der ML-Toolbox entweder auf PLS oder OLS. Die Funktion Nullen und Ausreißer zu entfernen, ist voreingestellt. (Änderbar im Side-Menu "Einstellungen"). Falls Sie dies nicht wollen, müssen Sie die Funktion explizit deaktivieren. Zum Start der Berechnungssequenz klicken Sie auf den Button des Zielparameters in der Box "Zielwert". Nach der Berechnung ergibt sich folgendes Bild:
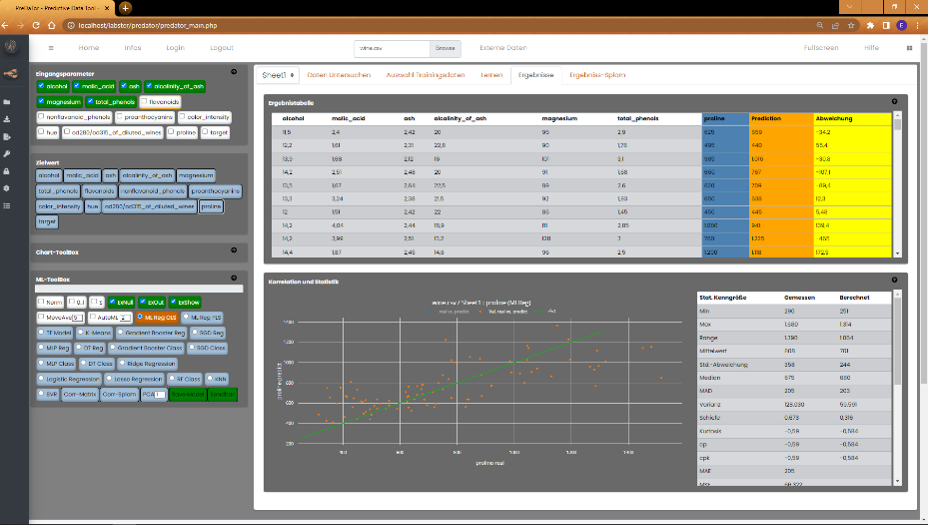 Was ist nun alles vor, während und nach der Berechnung passiert?
1) Bevor die Berechnungen losgehen, werden die Daten vorbereitet. Gemäß Einstellungen werden Nullen und Ausreißerdatensätze gelöscht. Ein weiterer
Schritt ist die Aufteilung der Datensätze in Trainings- und Validierungsdatensätze. In den Voreingestellungen ist festgelegt, das 75% der Datensätze für
das Trainieren des Modells verwendet werden sollen. Dieser Wert ist in den Einstellungen unter dem Reiter "Learner Optionen" frei wählbar. Der Anteil
der Trainingsdaten sollte jedoch den Wert 50% nicht unterschreiten. Der Rest der Datensätze wird für die spätere Validierung des Modells herangezogen.
Validierung bedeutet hier, dass die Vorhersagekraft des Modells anhand von unbekannten Daten bewertet wird. Die gesplitteten Datensätze werden im Reiter
"Auswahl Trainingsdaten" angezeigt.
Was ist nun alles vor, während und nach der Berechnung passiert?
1) Bevor die Berechnungen losgehen, werden die Daten vorbereitet. Gemäß Einstellungen werden Nullen und Ausreißerdatensätze gelöscht. Ein weiterer
Schritt ist die Aufteilung der Datensätze in Trainings- und Validierungsdatensätze. In den Voreingestellungen ist festgelegt, das 75% der Datensätze für
das Trainieren des Modells verwendet werden sollen. Dieser Wert ist in den Einstellungen unter dem Reiter "Learner Optionen" frei wählbar. Der Anteil
der Trainingsdaten sollte jedoch den Wert 50% nicht unterschreiten. Der Rest der Datensätze wird für die spätere Validierung des Modells herangezogen.
Validierung bedeutet hier, dass die Vorhersagekraft des Modells anhand von unbekannten Daten bewertet wird. Die gesplitteten Datensätze werden im Reiter
"Auswahl Trainingsdaten" angezeigt.
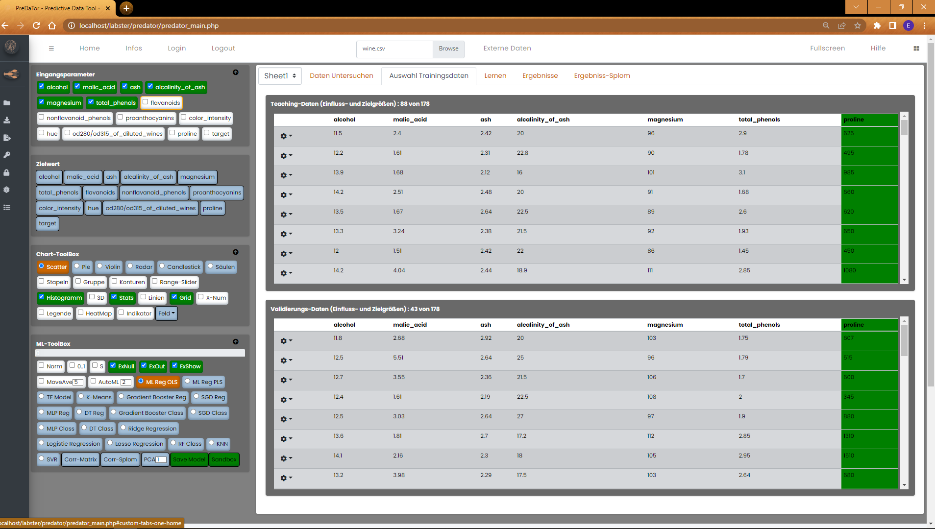 Hier können auch noch manuell ungewünschte Datensätze aus der aktuellen Tabelle entfernt werden. Die Daten in der ursprünglichen Datei bleiben dabei
erhalten. Die Datei wird als solche nicht verändert! Wurden die Daten nach Wunsch bereinigt, wird durch einen weiteren Klick auf den Zielparameter
die Modellberechnung aktualisiert.
2) Die Ergebnisse im Reiter "Ergebnisse" werden sowohl tabellarisch als auch graphisch dargestellt. Zusäzlich werden die Statistik und die Metrik der
Ergebnisse ebenfalls tabellarisch angezeigt. Die Ergebnistabelle zeigt neben den realen (Trainings-)Eingangsdaten und den realen Werten des Zielparameters
auch die Vorhersage "Prediction" und die resultierende Abweichung zum Realwert an.
Hier können auch noch manuell ungewünschte Datensätze aus der aktuellen Tabelle entfernt werden. Die Daten in der ursprünglichen Datei bleiben dabei
erhalten. Die Datei wird als solche nicht verändert! Wurden die Daten nach Wunsch bereinigt, wird durch einen weiteren Klick auf den Zielparameter
die Modellberechnung aktualisiert.
2) Die Ergebnisse im Reiter "Ergebnisse" werden sowohl tabellarisch als auch graphisch dargestellt. Zusäzlich werden die Statistik und die Metrik der
Ergebnisse ebenfalls tabellarisch angezeigt. Die Ergebnistabelle zeigt neben den realen (Trainings-)Eingangsdaten und den realen Werten des Zielparameters
auch die Vorhersage "Prediction" und die resultierende Abweichung zum Realwert an.
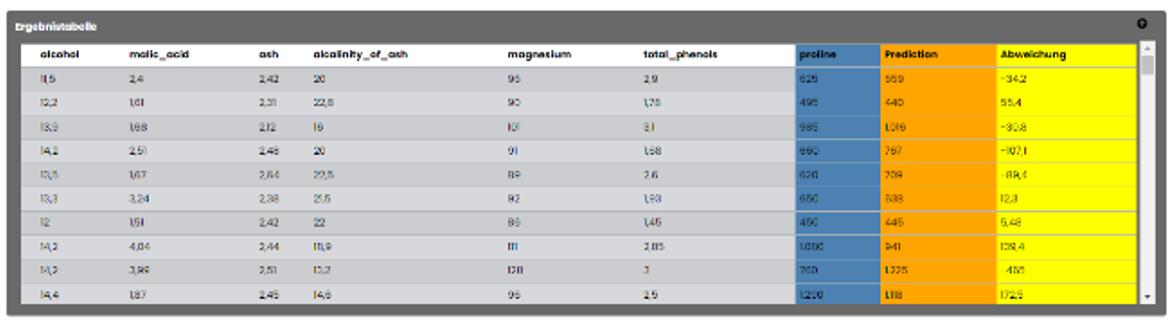 Die Gegenüberstellung des realen zum berechneten Wert des vorherzusagenden Zielparameters ist im Korrelationschart zu sehen. Die grüne Linie hat die theoretische
Korrelation von 1, d.h. alle Werte liegen auf der grünen Linie. Die orangenen Punkte sind die resultierenden Ergebnisse der Validierungsdatensätze zu den Abweichungen.
Die Koordinaten der Punkte sind : x = Ziel real | y = Ziel berechnet. Es ergibt sich ein Korrelationskoeffizient aus dieser linearen Beziehung, welcher für die
Güte der Vorhersage steht. Umso näher der Wert an der 1 liegt (100% Übereinstimmung), desto besser ist die Vorhersagekraft des Modells.
Die Gegenüberstellung des realen zum berechneten Wert des vorherzusagenden Zielparameters ist im Korrelationschart zu sehen. Die grüne Linie hat die theoretische
Korrelation von 1, d.h. alle Werte liegen auf der grünen Linie. Die orangenen Punkte sind die resultierenden Ergebnisse der Validierungsdatensätze zu den Abweichungen.
Die Koordinaten der Punkte sind : x = Ziel real | y = Ziel berechnet. Es ergibt sich ein Korrelationskoeffizient aus dieser linearen Beziehung, welcher für die
Güte der Vorhersage steht. Umso näher der Wert an der 1 liegt (100% Übereinstimmung), desto besser ist die Vorhersagekraft des Modells.
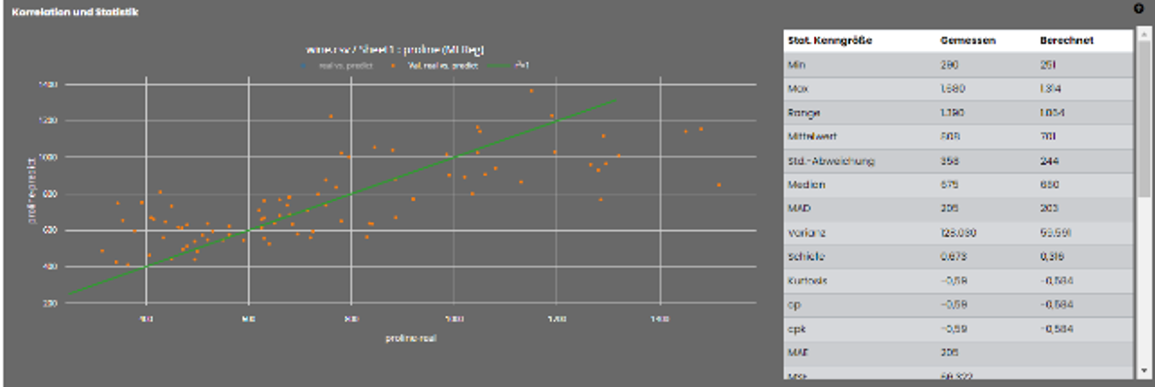 Rechts neben dem Chart, befindet sich die Stats-Box. Diese enthält die statistischen Kenngrößen der realen und des vorhergesagten Daten. Für Regressionen sollte
der Regressionskoeffizient r² als Qualitätsmasstab verwendet werden. Für Klassifizierungen eignet sich der Metrik-Wert "Accuracy" (Acc) sowie die
Metriken MSE und MAE (Std- und Average Error). Des weiteren finden Sie die Gewichtungen der einzelnen Eingangsparameter im unteren Teil der Tabelle.
Sie haben soeben ihr erstes Modell erstellt! Herzlichen Glückwunsch!
Jetzt zu der Sandbox - die Prozessimulation..
Rechts neben dem Chart, befindet sich die Stats-Box. Diese enthält die statistischen Kenngrößen der realen und des vorhergesagten Daten. Für Regressionen sollte
der Regressionskoeffizient r² als Qualitätsmasstab verwendet werden. Für Klassifizierungen eignet sich der Metrik-Wert "Accuracy" (Acc) sowie die
Metriken MSE und MAE (Std- und Average Error). Des weiteren finden Sie die Gewichtungen der einzelnen Eingangsparameter im unteren Teil der Tabelle.
Sie haben soeben ihr erstes Modell erstellt! Herzlichen Glückwunsch!
Jetzt zu der Sandbox - die Prozessimulation..
-
Quick Start - Sandbox
Die Sandbox erlaubt es Ihnen, das berechnete Modell anhand von beliebigen Daten zu testen.
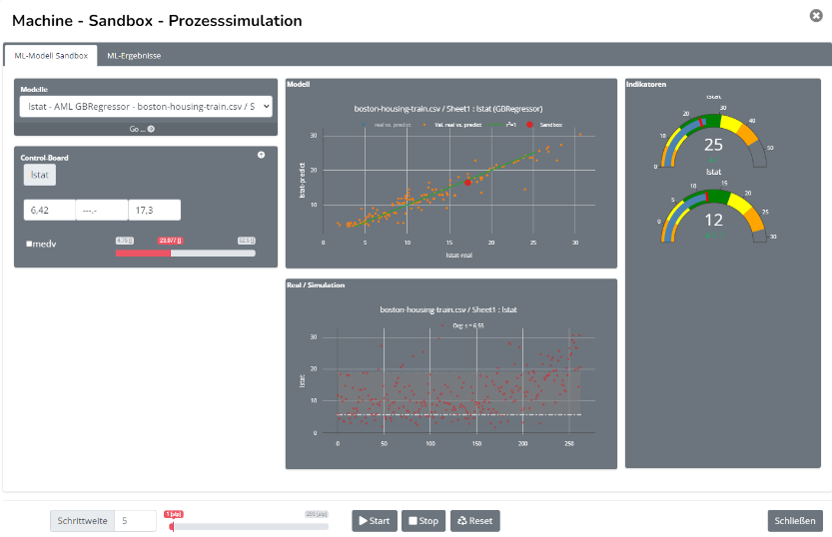 Unabhängig von der PreDaTor-Version, steht Ihnen die Sandbox immer zu Verfügung. Der Unterschied zwischen Basic und Pro besteht in der Möglichkeit, das erstellte
Modell in der PreDaTor Datenbank abzuspeichern und später wieder zu verwenden. Pro-Anwender speichern das erstellte Modell über den "Save Model"-Button in der
"ML-Toolbox", bzw. auch lineare Regressionsmodelle im "Stats-Modul".
Sowohl in der Basic- als auch der Pro-Version aktivieren Sie die Sandbox über den Button in der "ML-Toolbox" nach erfolgreicher Erstellung des Modells.
Das aktuelle Modell wird geladen und visuell dargestellt. In der linken Sektion befindet sich die Auswahlbox der gespeicherten Modelle (Pro-Version).
Darunter befindet sich das Control-Panel für die Prozesssimulation. Die Schieberegler sind gemäß des Daten-Ranges der Eingangsdaten beschriftet und skaliert.
Über die Schieberegler erstellen Sie den Eingangsdatensatz, welcher in das Modell gespeist wird. Der resultirende Zielwert wird automatisch berechnet und
im Chart in der "Modell"-Box als rote Markierung angezeigt.
Unabhängig von der PreDaTor-Version, steht Ihnen die Sandbox immer zu Verfügung. Der Unterschied zwischen Basic und Pro besteht in der Möglichkeit, das erstellte
Modell in der PreDaTor Datenbank abzuspeichern und später wieder zu verwenden. Pro-Anwender speichern das erstellte Modell über den "Save Model"-Button in der
"ML-Toolbox", bzw. auch lineare Regressionsmodelle im "Stats-Modul".
Sowohl in der Basic- als auch der Pro-Version aktivieren Sie die Sandbox über den Button in der "ML-Toolbox" nach erfolgreicher Erstellung des Modells.
Das aktuelle Modell wird geladen und visuell dargestellt. In der linken Sektion befindet sich die Auswahlbox der gespeicherten Modelle (Pro-Version).
Darunter befindet sich das Control-Panel für die Prozesssimulation. Die Schieberegler sind gemäß des Daten-Ranges der Eingangsdaten beschriftet und skaliert.
Über die Schieberegler erstellen Sie den Eingangsdatensatz, welcher in das Modell gespeist wird. Der resultirende Zielwert wird automatisch berechnet und
im Chart in der "Modell"-Box als rote Markierung angezeigt.